Read before write et les frameworks

Le pattern read before write est assez commun lorsqu’il s’agit de mettre à jour des données en fonction de règles implémentées dans un langage de programmation quelconque. Dans le cas où les requêtes sont exécutées en parallèle, il y a plusieurs cas de figure :
- lorsqu’on utilise des librairies (c’est moi qui appelle la librairie), on pourra toujours gérer localement
- lorsqu’on utilise des frameworks (je me fait appeler par le framework), la gestion devient un peu moins centralisée
Dans cet article, je reviens sur un bug constaté dans le cas 2., comment j’ai pu le résoudre et quelles conséquences pour la maintenabilité.
Contexte
Lorsqu’on développe un produit dans lequel des utilisateurs peuvent se connecter et interagir, il est très fréquent de vouloir synchroniser cette liste d’utilisateurs avec un système tiers. Ce besoin se fait d’autant plus sentir lorsque ces utilisateurs sont nombreux et sont organisés dans des groupes. Le standard System for Cross-domain Identity Management (SCIM) est né dans ce cadre et j’ai été amené à l’implémenter au moyen d’un framework/middleware Java nommé SCIM-SDK et maintenu par Pascal Knüppel.
Problème
Lorsqu’un client SCIM démarre une synchronisation, il peut initier des requêtes de ce type :
PATCH https://example.com/v2/Groups/Group1
Authorization: Bearer eyJ0...dFx4
Content-Type: application/scim+json
{
"schemas": ["urn:ietf:params:scim:api:messages:2.0:PatchOp"],
"Operations": [
{
"op": "add",
"path": "members",
"value": {"value": "User2"}
}
]
}
Il s’agit d’un PATCH (un verbe du protocole HTTP qui permet de mettre à jour une ressource). Cette opération d’ajout d’un utilisateur à un groupe est donc une mise à jour incrémentale. Ça tombe bien, car mon système en backend travaille lui aussi en incrémental en me permettant d’ajouter ou de supprimer unitairement un utilisateur à un groupe.
En revanche SCIM-SDK ne le voit pas tout-à-fait de la même manière et je me fais appeler sur un resourceHandler.getResource avant de me
faire appeler sur resourceHandler.updateResource.
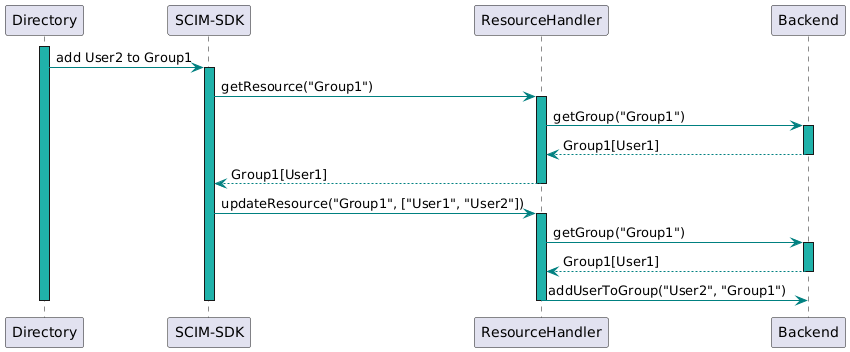
On est donc ici en présence de deux éléments importants sur lesquels je vais revenir plus tard :
- read before write : le composant récupère l’état d’une resource avant de la mettre à jour
- framework : on détecte qu’il s’agit d’un framework lorsqu’on traduit ce qu’il se passe par je me fais appeler plutôt que j’appelle (ce qui est le cas d’une libraire).
Pour finir de décrire le problème, imaginez maintenant que la synchronisation du système se fait en parallèle sans vraiment attendre que chaque requête de modification aboutisse avant d’enchaîner avec la suivante et vous obtenez un groupe où il manque des utilisateurs.
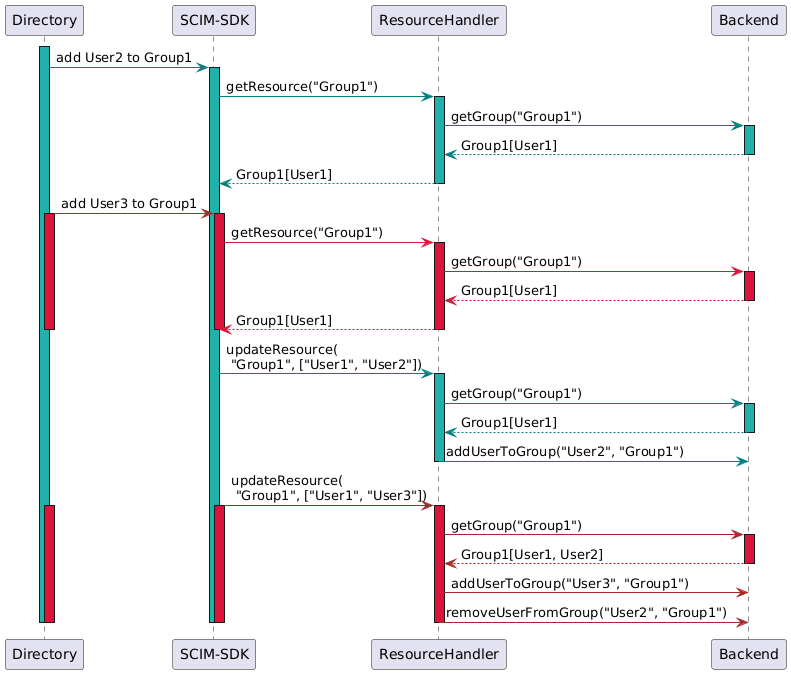
Le bug ici est visible par le fait que mon ResourceHandler est obligé de demander à nouveau la liste des membres de Group1. Celle-ci
ayant évoluée depuis l’appel précédent, ResourceHandler en déduit qu’il faut non seulement ajouter User3 à Group1 mais également
supprimer User2 de Group1.
Solution
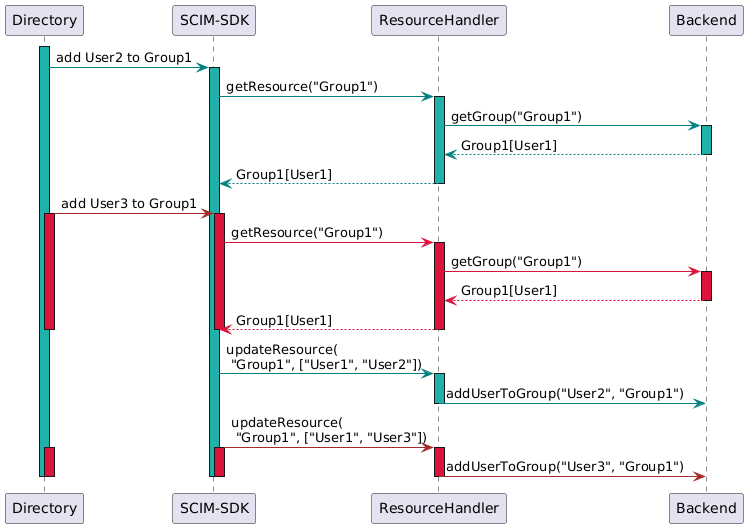
J’aurais aimé que la solution ait été de supprimer la nécessité pour le framework de calculer lui-même la liste des membres d’un groupe et ainsi éviter ce pattern read before write. Mais dans le temps imparti, la solution la plus simple fut d’utiliser la capacité du framework d’adjoindre un contexte de requête à chaque appel. Ainsi, on place dans le contexte la liste des membres du groupe lors du premier appel. Le framework calcule sa liste finale de membres à partir de cette vérité. Puis je me fais rappeler sur cette nouvelle liste. Plutôt que de demander à nouveau la liste des membres du groupe au backend, je ne fais confiance qu’à liste précédemment retournée et enregistrée dans le contexte de la requête. L’effet de bord intéressant est d’économiser des appels en lecture devenus inutiles.
Voici donc l’enchaînement des requêtes avec le contexte :
Conclusion
La description du problème nous a permis de décrire deux éléments que je trouve important à avoir en tête lorsqu’on met au point un système :
- read before write : on souhaite éviter au maximum de récupérer l’état d’un élément avant de demander au système auquel il appartient de le modifier. Cela permet d’éviter des soucis lorsque le système est utilisé de manière concurrente. On peut parfois lire des considérations similaires en se référant à tell, don’t ask.
- framework : on sait maintenant détecter un framework car c’est lui qui nous appelle. C’est pour cela que je préfère toujours utiliser des librairies plutôt que des frameworks. Il est plus facile de contourner un bug ou une manière de gérer un cas non prévu par le composant tiers si on a la main sur l’appel plutôt que si on est obligé d’être passif et d’attendre de se faire appeler.